Interactive Demo
Text Prompt:
Spell the word
See, Plan, Predict: Language-guided Cognitive Planning with Video Prediction
[Code] [Paper] (Coming soon!)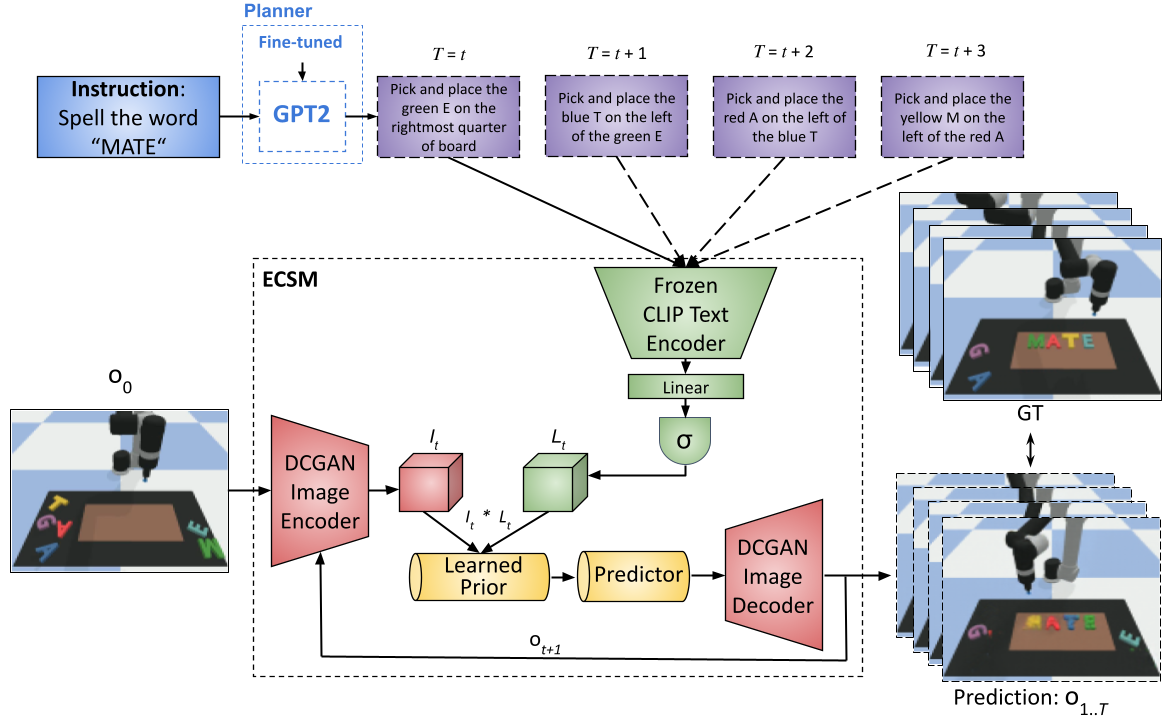
In order to assess the importance of the two submodules of our system, two ablation studies were performed. Results with absence of a planner indicate that often high level task descriptions do not contain enough information to perform the task and highlight the value of a planner breaking down a task into lower level actions. Substituting pre-trained natural language embeddings with one-hot encodings as the language representation of choice also demonstrates the power of language embeddings pre-trained in tandem with visual embeddings, for concept learning.

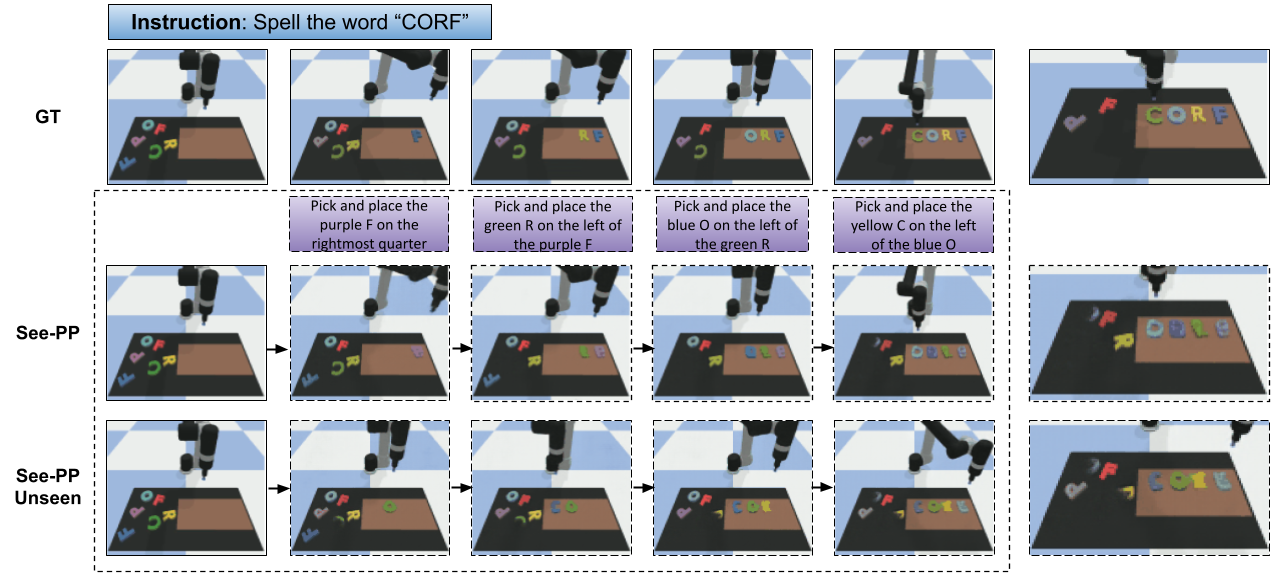
Generalization results on the Spelling dataset. Language instructions are passed in along with the initial visual observation. Comparison between 3 models, See-PP trained on a random train/test split, See-PP trained on a seen/unseen train/test split where 4 letters (F, Q, X, Z) were kept unseen during training.
Two modes of prediction. Dense prediction is longer horizon and aims to generate smoother transitions and more realistic videos. Keyframe prediction is shorter horizon and, while more fragmented, can yield better results that can be useful towards low level control in robotic settings, through Imitation Learning approaches.